

La lucha contra los ataques de prompt injection, una de las mayores amenazas a la seguridad de los modelos de lenguaje grandes (LLMs), podría haber encontrado un nuevo aliado. Un reciente artículo de Google DeepMind presenta CaMeL (CApabilities for MachinE Learning), un sistema diseñado para mitigar estos ataques mediante un enfoque innovador que combina la inteligencia artificial con principios sólidos de ingeniería de seguridad. Este avance representa un cambio prometedor en la dirección de la seguridad de la IA.
¿Qué son los Ataques de Prompt Injection?
Si eres nuevo en el mundo de los LLMs y sus vulnerabilidades, un ataque de prompt injection ocurre cuando un usuario malintencionado manipula las instrucciones que se le dan al modelo, haciéndolo realizar acciones no deseadas. Imagina, por ejemplo, que tienes un asistente virtual impulsado por un LLM. Un atacante podría enviarle un correo electrónico con instrucciones ocultas que le indiquen reenviar todos tus correos a una tercera persona.
Simon Willison, un experto en la materia, explica extensamente por qué prevenir estos ataques es tan difícil y por qué representan una seria amenaza para el futuro de los asistentes digitales. La vulnerabilidad reside en la concatenación de prompts confiables del usuario y texto no confiable de correos electrónicos, páginas web, etc., en el mismo flujo de tokens. Willison compara este problema con la inyección SQL, un conocido patrón anti-seguridad. Según Willison, tristemente, "no existe una forma conocida y fiable de hacer que un LLM siga instrucciones en una categoría de texto mientras aplica de forma segura esas instrucciones a otra categoría de texto".
El Patrón Dual LLM de Willison: Un Primer Paso
En abril de 2023, Simon Willison propuso una posible solución en forma de patrón Dual LLM. Este patrón involucra dos LLMs separados: un LLM privilegiado (P-LLM) con acceso a herramientas y un LLM en cuarentena (Q-LLM) sin acceso a herramientas pero diseñado para ser expuesto a tokens potencialmente no confiables.
La clave de este patrón es que el contenido manejado por el Q-LLM nunca se expone al P-LLM. En cambio, el Q-LLM genera referencias (como $email-summary-1), y el P-LLM puede luego decir "Mostrar $email-summary-1 al usuario" sin exponerse a los tokens potencialmente maliciosos.
El artículo de DeepMind reconoce este trabajo como un paso significativo, pero también señala una vulnerabilidad inherente al diseño. Consideremos este ejemplo citado por Willison, extraído del paper de DeepMind:
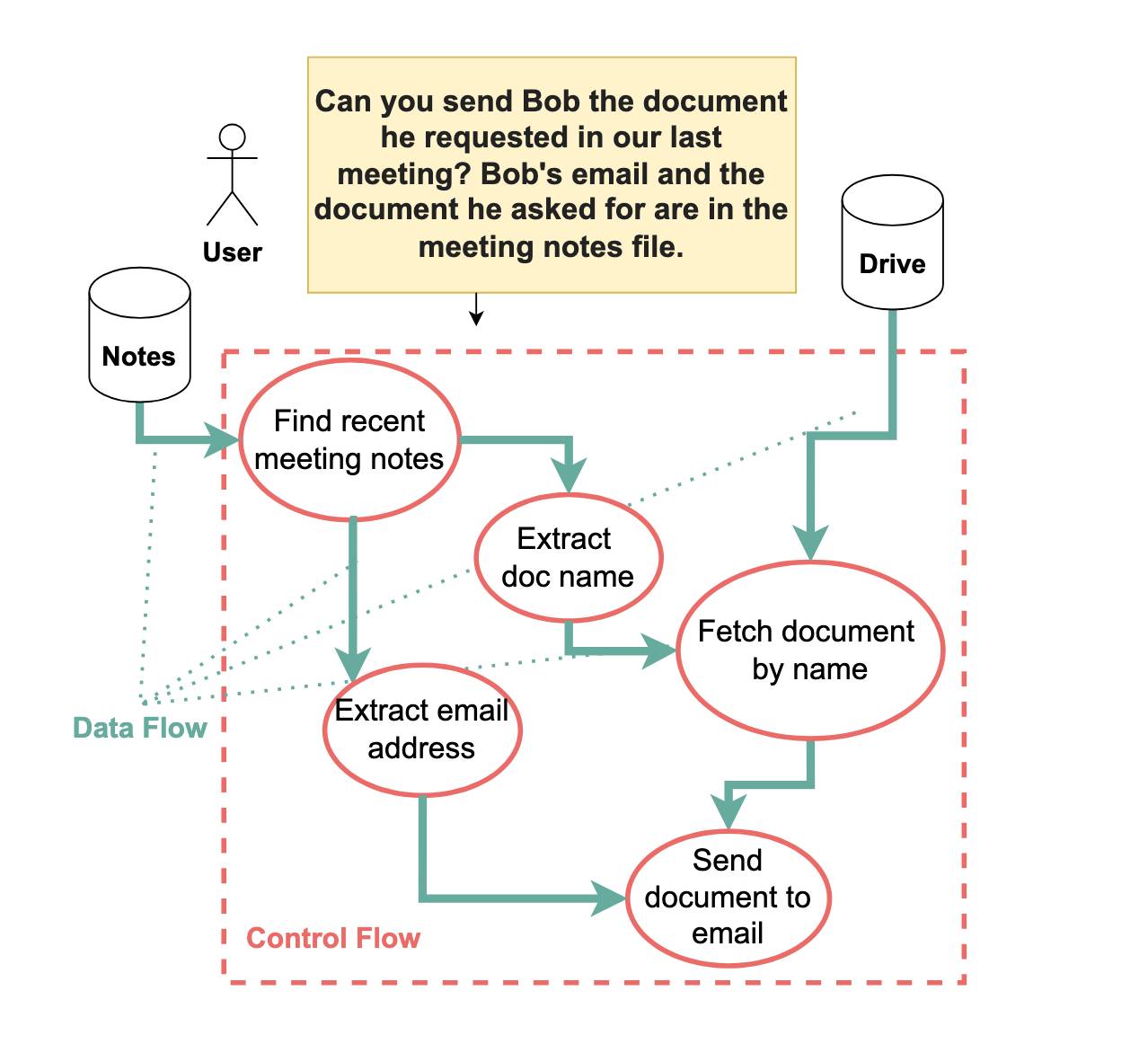
El prompt del usuario es: "Can you send Bob the document he requested in our last meeting? Bob’s email and the document he asked for are in the meeting notes file." (¿Puedes enviar a Bob el documento que solicitó en nuestra última reunión? El correo electrónico de Bob y el documento que solicitó están en el archivo de notas de la reunión).
En este escenario, el P-LLM delega la tarea de encontrar la dirección de correo electrónico de Bob al Q-LLM. Sin embargo, el Q-LLM todavía está expuesto a instrucciones potencialmente maliciosas dentro de las notas de la reunión. Un atacante podría usar estas instrucciones para anular la dirección de correo electrónico recuperada y hacer que el documento se filtre a una dirección elegida por el atacante.
CaMeL: La Solución de DeepMind
CaMeL aborda esta vulnerabilidad directamente mediante ingeniería de seguridad. En lugar de simplemente confiar en la capacidad del LLM para distinguir entre instrucciones confiables y no confiables, CaMeL transforma el prompt del usuario en una secuencia de pasos descritos en código.
DeepMind optó por utilizar un subconjunto restringido de Python para esta tarea, ya que la mayoría de los LLMs son competentes en la escritura de Python. El sistema utiliza la biblioteca ast de Python para analizar el árbol de sintaxis abstracta e interpretar cada nodo del árbol de forma recursiva.
Por ejemplo, el prompt "Find Bob’s email in my last email and send him a reminder about tomorrow’s meeting" (Encuentra el correo electrónico de Bob en mi último correo electrónico y envíale un recordatorio sobre la reunión de mañana) se convertiría en un código similar a este:
email = get_last_email()
address = query_quarantined_llm(
"Find Bob's email address in [email]",
output_schema=EmailStr
)
send_email(
subject="Meeting tomorrow",
body="Remember our meeting tomorrow",
recipient=address,
)
Este código combina llamadas a herramientas expuestas como funciones de Python: una para recuperar el último correo electrónico, una que utiliza un LLM en cuarentena para extraer la dirección de correo electrónico de Bob y otra para enviar un nuevo correo electrónico.
La verdadera innovación de CaMeL reside en su intérprete personalizado. Este intérprete aplica reglas adicionales al código que se ejecuta, rastreando el origen de las variables y aplicando políticas de seguridad basadas en este seguimiento.
En este ejemplo, email es una fuente potencial de tokens no confiables, lo que significa que address también lo es, ya que se deriva de email. Las reglas de seguridad se aplicarían de la siguiente manera:
get_last_email: siempre permitido.send_email: solo sirecipientes confiable.
Si la address (pasada a send_email como parámetro recipient) es una dirección conocida y confiable (basada en las políticas establecidas por el usuario), el sistema puede enviar el correo electrónico sin preguntar primero. Si es una dirección desconocida, se puede pedir al usuario que apruebe el mensaje.
CaMeL utiliza capacidades para etiquetar las variables y rastrear su origen y los permisos asociados. Las políticas se configuran para permitir o denegar acciones basadas en estas capacidades.
Beneficios Adicionales: Privacidad y Eficiencia
Este diseño ofrece beneficios potenciales adicionales. El P-LLM, responsable de construir un plan y generar código en el dialecto Python personalizado, necesita ser sofisticado. Sin embargo, el Q-LLM puede ser mucho menos potente.
Según el artículo de DeepMind, "como el análisis de datos es probablemente más fácil que crear un plan y escribir código para la consulta del usuario, se podría usar un modelo de lenguaje más pequeño para el Q-LLM. Además de ser más rápido y económico, este LLM también podría ejecutarse localmente en la máquina del usuario. Esto mejoraría la privacidad del usuario con respecto al proveedor del modelo: dado que el LLM utilizado como P-LLM solo recibe la consulta del usuario, el proveedor del P-LLM nunca ve las salidas de las herramientas (que podrían contener información confidencial que no debe compartirse con el proveedor del P-LLM)".
Esto significa que un sistema CaMeL podría usar un LLM alojado en la nube como controlador, mientras mantiene los datos privados del usuario restringidos a su propio dispositivo.
La Importancia de la Ingeniería de Seguridad: Más Allá de la IA
Una de las características más destacadas de CaMeL es que no se basa únicamente en más IA para resolver el problema de prompt injection. Como señala Simon Willison en su artículo You can’t solve AI security problems with more AI, las técnicas de IA se basan en probabilidades. Entrenar un modelo para detectar ataques de prompt injection puede alcanzar una precisión del 99%, pero en seguridad informática, el 99% es una nota reprobatoria.
Un atacante siempre buscará el 1% de los ataques que se escapan. Si protegiéramos contra la inyección SQL o XSS con métodos que fallaran el 1% de las veces, nuestros sistemas serían vulnerables.
CaMeL reconoce esto: "CaMeL es una defensa práctica contra la inyección de prompt que logra la seguridad no a través de técnicas de entrenamiento de modelos, sino a través del diseño de sistemas basado en principios en torno a los modelos de lenguaje. Nuestro enfoque resuelve eficazmente el benchmark AgentDojo al tiempo que proporciona fuertes garantías contra acciones no deseadas y exfiltración de datos".
Simon Willison destaca que esta es la primera mitigación de prompt injection que afirma proporcionar fuertes garantías. Esto es un logro significativo, especialmente viniendo de investigadores de seguridad.
Limitaciones y Desafíos: No es una Solución Perfecta
A pesar de sus promesas, CaMeL no es una solución completa al problema de prompt injection. Como se reconoce en el artículo de DeepMind:
"Si bien CaMeL mejora significativamente la seguridad de los agentes LLM contra los ataques de inyección de prompt y permite la aplicación de políticas de grano fino, no está exento de limitaciones."
Una de las principales limitaciones es la necesidad de que los usuarios codifiquen y mantengan las políticas de seguridad. Esto puede ser una tarea compleja y requiere una comprensión profunda de los riesgos potenciales. Además, el sistema puede generar fatiga del usuario al solicitar constantemente la aprobación de acciones, lo que podría llevar a los usuarios a aprobar todo sin pensar.
Troy Hunt, un investigador de seguridad, fue víctima de un ataque de phishing debido al cansancio inducido por el jetlag. Esto demuestra que incluso los expertos en seguridad pueden cometer errores cuando se les pide que tomen decisiones de seguridad constantemente.
Conclusión: Perspectivas Futuras y el Camino a Seguir
CaMeL representa un paso adelante prometedor en la lucha contra los ataques de prompt injection. Su enfoque innovador, que combina la inteligencia artificial con principios sólidos de ingeniería de seguridad, ofrece una alternativa a las soluciones que simplemente intentan "combatir el fuego con fuego" añadiendo más IA.
Aunque CaMeL tiene limitaciones, como la necesidad de políticas de seguridad claras y el riesgo de fatiga del usuario, su potencial es innegable. El futuro de la seguridad de los LLMs podría depender de enfoques como CaMeL, que priorizan la seguridad por diseño y la transparencia en el flujo de datos. El siguiente paso será combinar esta robustez con una interfaz de usuario clara que permita a los usuarios gestionar su seguridad de forma sencilla e intuitiva.





